
L’automatisation des tests de non-régression (TNR) peut être mise en place assez facilement (avec un peu de développement quand même) à partir de fichiers XML. Dans mon ancienne équipe, les TNR étaient joués à la main, à l’aide d’un comparateur de fichiers XML qui produisait un rapport de différences. Nous avons décidé d’investir dans l’automatisation, ce qui nous a permis d’augmenter le périmètre des TNR et surtout de pouvoir les jouer à volonté. Je partage dans cet article le processus que nous avons mis en place pour vérifier tous les jours plusieurs milliers de calculs.
Votre système n’utilise pas de fichier XML ?
Même si votre système n’utilise pas de fichier XML en entrée et/ou en sortie, il peut être intéressant d’installer des traducteurs XML aux entrées et aux sorties. Cela correspond à donner à votre application la possibilité de lire et produire deux types d’entrée et de sortie. L’un au format habituel et l’autre au format XML.
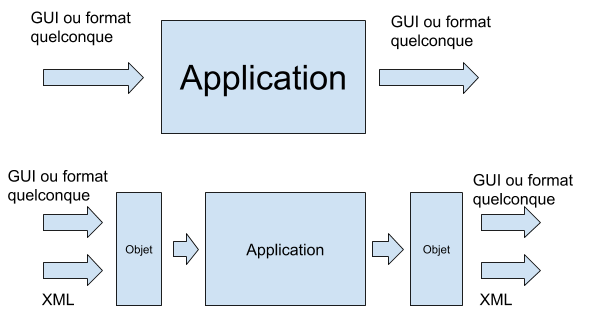
Dans ce cas, les fichiers XML ne seront utilisés que pour tester la non-régression. Ils ne seront jamais utilisés en production.
Automatiser les tests de non-régression peut se mener en plusieurs étapes, chacune offrant une valeur progressive à votre équipe de testeur. Voici comment peut se décomposer la construction de l’automatisation des TNR:
- Automatiser l’envoie de fichier XML à l’application
- Automatiser la comparaison de fichiers XML
- Organiser les données de test
- Filtrer les données à comparer
- Versionner les données de test
- Améliorer en continue l’automate de test
- Faire évoluer le rôle des testeurs
- Rester proche de la réalité de production
1. Automatiser l’envoie de fichiers XML à l’application
Automatiser l’envoie de plusieurs fichiers XML à l’application offre un premier gain aux testeurs. En effet, ils n’ont plus qu’à solliciter l’application une seule fois pour générer l’ensemble des fichiers XML à comparer.
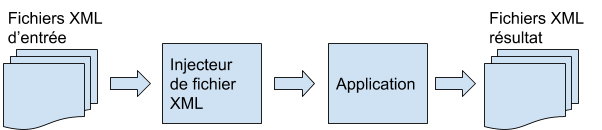
Il s’agira ici de construire un programme “Injecteur de fichier XML” capable d’envoyer successivement plusieurs fichiers XML d’entrée (correspondant à différents scénarios) à votre application de sorte à ce qu’elle produise des fichiers de résultat correspondant à ces scénarios. La comparaison de fichiers XML résultat avec des fichiers XML de référence reste ici manuelle.
2. Automatiser la comparaison de fichiers XML
L’algorithme de comparaison de fichier XML est assez compliqué. Je recommande l’usage de bibliothèques spécialisées plutôt que d’essayer de développer cet outil soi-même. A l’époque (en 2012), je m’étais tourné vers l’outil de Microsoft Xml Diff and Patch Tool.
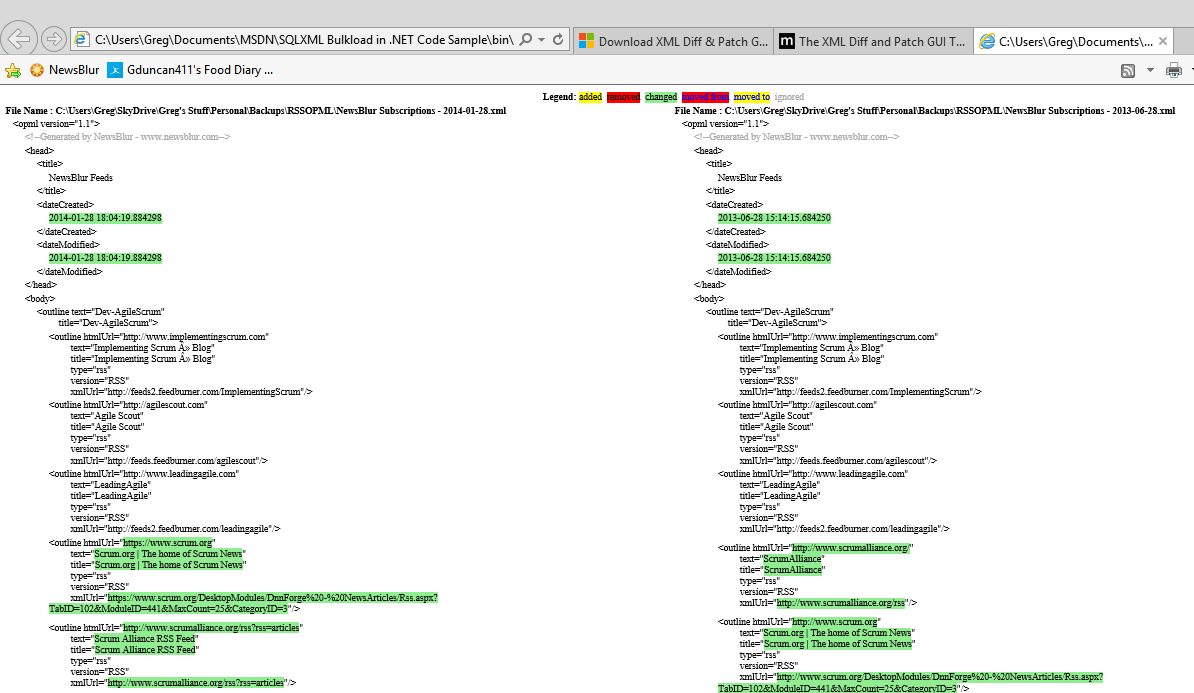
L’outil mentionné ci-dessus permet de générer un fichier HTML présentant les différences entre deux fichiers XML. Il précise les différents types de différences comme l’ajout, la suppression, la modification et le déplacement de données XML.
Automatiser la comparaison de fichiers XML revient à être capable non seulement d’injecter des fichiers XML en entrée de l’application mais aussi de récupérer les fichiers XML résultats produit par cette dernière et les comparer à des fichiers XML de référence.
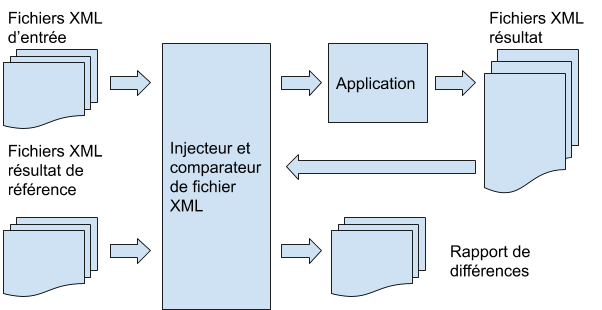
3. Organiser les données de test
L’ensemble des données de test peuvent être stockées dans des dossiers, eux même rangés dans un dossier racine représentant la version de l’application / du système à tester.
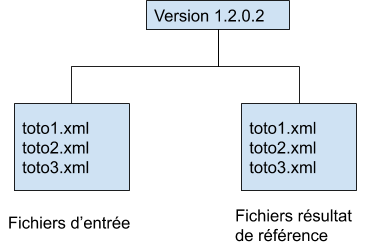
Ainsi, en précisant à l’injecteur l’adresse du dossier de test ainsi que celle du dossier où sont produits les fichiers résultats, l’outil est capable d’envoyer successivement les fichiers XML à l’application et comparer les fichiers générés par l’application à des fichiers de référence. Pour identifier facilement les fichiers à comparer, le mieux est de donner un nom similaire aux fichiers d’entrée, de résultat et de référence.
4. Filtrer les données à comparer
Les dates et certaines données varient systématiquement entre deux compagnes de test. Si ces données n’ont pas besoin de faire partie de l’analyse, il est préférable de les enlever des fichiers XML avant le processus de comparaison.
Pour filtrer les fichier XML, il est possible de lister les données à supprimer dans un fichier. Ce dernier sera lu par l’injecteur-comparateur, qui supprimera les attributs et les éléments ciblé par d’expressions xPaths.

Il est possible d’aller plus loin dans la comparaison en proposant un interval de tolérance sur certaines données afin que l’outil ne signale pas d’erreur sur certaines valeurs légèrement différentes.
5. Versionner les données de test
Les données de test doivent être versionnées, au même titre que l’application à tester. Ainsi, comme vous souhaitez tester la non-régression de la version de production (au cas où il y ait une correction de bug à effectuer) et celle de la version en cours de développement, il vous faut maintenir au moins deux jeux de tests de non-régression.
La version en cours de développement permettra de détecter des différences normales par rapport aux résultats des tests de la version précédente. L’équipe de test modifiera les données de test de référence pour la nouvelle version de l’application de sorte à ce que ces différences normales n’existent plus.
6. Améliorer en continue l’automate de test
La construction de l’automate de test (l’injecteur-comparateur) doit se faire de manière incrémentale. Il est possible de démarrer cette initiative en lui consacrant un peu de temps chaque semaine et en visant de petits objectifs qui, mis bout à bout, transformeront complètement la manière de tester la non-régression de l’application. Ainsi, vous pouvez commencer simplement par automatiser l’injection de fichier XML, ce qui apporte déjà de la valeur aux testeurs. Vous pouvez améliorer leur outil de comparaison de fichier XML jusqu’à le rendre capable de comparer un lot de fichiers XML avec des fichiers de référence. Vous pouvez ensuite coupler l’injecteur de fichier XML avec l’outil de comparaison afin de n’avoir qu’à appuyer sur un bouton pour lancer les TNR. Vous pouvez aussi vous intéresser à la manière d’installer et configurer automatiquement le système à tester sur un environnement physique ou virtuel et par la suite à l’infrastructure as code afin de jouer les TNR sur un environnement éphémère que vous aurez construit puis détruit une fois le résultat des tests obtenus. Vous pouvez enfin intégrer tout cela dans un pipeline de déploiement et commencer à réfléchir sérieusement à une stratégie de livraison continue.
7. Faire évoluer le rôle des testeurs
Le rôle des testeurs évolue au fur et à mesure de la construction de l’automate. Il est intéressant de les considérer comme les premiers utilisateurs, voir comme les product owners de ce nouvel outil. Au tout début, les testeurs passaient beaucoup de temps sur des actions manuelles et répétitives. Petit à petit, leurs activités se sont concentrées sur l’analyse des rapports de test et l’amélioration de l’automate avec comme préoccupation de rendre les TNR de plus en plus facile à réaliser et de produire des rapports de différence toujours plus précis. Le rôle du testeur ne disparaît donc pas avec l’automatisation des TNR; leurs activités peuvent se transformer en quelque chose de plus passionnant s’ils sont complètement embarqués dans l’aventure de l’automatisation.
8. Rester proche de la réalité de production
Il est essentiel d’avoir des données de test représentatives de la production. Ainsi, il vous faut mener régulièrement des campagnes d’analyse des données de production afin de mesurer la pertinence des données de test. Vous découvrez peut être que certaines fonctionnalités ne sont plus utilisées et qu’il est sans doute utile de les enlever de l’application, de même que leurs données de test associées. Le Feature usage tracking est une bonne pratique pour comprendre la manière dont sont utilisées les fonctionnalités en production. Cette pratique peut aider à identifier les scénarios importants pour les ajouter aux données de TNR ou au contraire à enlever ceux qui n’ont plus d’utilité.
Conclusion
L’automatisation des TNR ne se fait pas en un jour mais ce n’est pas quelque chose de compliqué si on se donne comme objectif d’y aller par petit pas et surtout en impliquant les testeurs. La proposition de cet article est de couvrir une grande partie des tests de non-régression en traversant l’application à l’aide de multiple scénarios. Il restera à imaginer des stratégies complémentaires pour tester les autres manières de solliciter l’application, à partir de l’interface utilisateur par exemple.
photo credit: mout1234 Engrenage au Musée des Arts et métiers via photopin (license)
L’automatisation des tests de non-régression (TNR) peut être mise en place assez facilement (avec un peu de développement quand même) à partir de fichiers XML. Dans mon ancienne équipe, les TNR étaient joués à la main, à l’aide d’un comparateur de fichiers XML qui produisait un rapport de différences. Nous avons décidé d’investir dans l’automatisation, ce qui nous a permis d’augmenter le périmètre des TNR et surtout de pouvoir les jouer à volonté. Je partage dans cet article le processus que nous avons mis en place pour vérifier tous les jours plusieurs milliers de calculs.
Votre système n’utilise pas de fichier XML ?
Même si votre système n’utilise pas de fichier XML en entrée et/ou en sortie, il peut être intéressant d’installer des traducteurs XML aux entrées et aux sorties. Cela correspond à donner à votre application la possibilité de lire et produire deux types d’entrée et de sortie. L’un au format habituel et l’autre au format XML.
Dans ce cas, les fichiers XML ne seront utilisés que pour tester la non-régression. Ils ne seront jamais utilisés en production.
Automatiser les tests de non-régression peut se mener en plusieurs étapes, chacune offrant une valeur progressive à votre équipe de testeur. Voici comment peut se décomposer la construction de l’automatisation des TNR:
- Automatiser l’envoie de fichier XML à l’application
- Automatiser la comparaison de fichiers XML
- Organiser les données de test
- Filtrer les données à comparer
- Versionner les données de test
- Améliorer en continue l’automate de test
- Faire évoluer le rôle des testeurs
- Rester proche de la réalité de production
1. Automatiser l’envoie de fichiers XML à l’application
Automatiser l’envoie de plusieurs fichiers XML à l’application offre un premier gain aux testeurs. En effet, ils n’ont plus qu’à solliciter l’application une seule fois pour générer l’ensemble des fichiers XML à comparer.
Il s’agira ici de construire un programme “Injecteur de fichier XML” capable d’envoyer successivement plusieurs fichiers XML d’entrée (correspondant à différents scénarios) à votre application de sorte à ce qu’elle produise des fichiers de résultat correspondant à ces scénarios. La comparaison de fichiers XML résultat avec des fichiers XML de référence reste ici manuelle.
2. Automatiser la comparaison de fichiers XML
L’algorithme de comparaison de fichier XML est assez compliqué. Je recommande l’usage de bibliothèques spécialisées plutôt que d’essayer de développer cet outil soi-même. A l’époque (en 2012), je m’étais tourné vers l’outil de Microsoft Xml Diff and Patch Tool.
L’outil mentionné ci-dessus permet de générer un fichier HTML présentant les différences entre deux fichiers XML. Il précise les différents types de différences comme l’ajout, la suppression, la modification et le déplacement de données XML.
Automatiser la comparaison de fichiers XML revient à être capable non seulement d’injecter des fichiers XML en entrée de l’application mais aussi de récupérer les fichiers XML résultats produit par cette dernière et les comparer à des fichiers XML de référence.
3. Organiser les données de test
L’ensemble des données de test peuvent être stockées dans des dossiers, eux même rangés dans un dossier racine représentant la version de l’application / du système à tester.
Ainsi, en précisant à l’injecteur l’adresse du dossier de test ainsi que celle du dossier où sont produits les fichiers résultats, l’outil est capable d’envoyer successivement les fichiers XML à l’application et comparer les fichiers générés par l’application à des fichiers de référence. Pour identifier facilement les fichiers à comparer, le mieux est de donner un nom similaire aux fichiers d’entrée, de résultat et de référence.
4. Filtrer les données à comparer
Les dates et certaines données varient systématiquement entre deux compagnes de test. Si ces données n’ont pas besoin de faire partie de l’analyse, il est préférable de les enlever des fichiers XML avant le processus de comparaison.
Pour filtrer les fichier XML, il est possible de lister les données à supprimer dans un fichier. Ce dernier sera lu par l’injecteur-comparateur, qui supprimera les attributs et les éléments ciblé par d’expressions xPaths.
Il est possible d’aller plus loin dans la comparaison en proposant un interval de tolérance sur certaines données afin que l’outil ne signale pas d’erreur sur certaines valeurs légèrement différentes.
5. Versionner les données de test
Les données de test doivent être versionnées, au même titre que l’application à tester. Ainsi, comme vous souhaitez tester la non-régression de la version de production (au cas où il y ait une correction de bug à effectuer) et celle de la version en cours de développement, il vous faut maintenir au moins deux jeux de tests de non-régression.
La version en cours de développement permettra de détecter des différences normales par rapport aux résultats des tests de la version précédente. L’équipe de test modifiera les données de test de référence pour la nouvelle version de l’application de sorte à ce que ces différences normales n’existent plus.
6. Améliorer en continue l’automate de test
La construction de l’automate de test (l’injecteur-comparateur) doit se faire de manière incrémentale. Il est possible de démarrer cette initiative en lui consacrant un peu de temps chaque semaine et en visant de petits objectifs qui, mis bout à bout, transformeront complètement la manière de tester la non-régression de l’application. Ainsi, vous pouvez commencer simplement par automatiser l’injection de fichier XML, ce qui apporte déjà de la valeur aux testeurs. Vous pouvez améliorer leur outil de comparaison de fichier XML jusqu’à le rendre capable de comparer un lot de fichiers XML avec des fichiers de référence. Vous pouvez ensuite coupler l’injecteur de fichier XML avec l’outil de comparaison afin de n’avoir qu’à appuyer sur un bouton pour lancer les TNR. Vous pouvez aussi vous intéresser à la manière d’installer et configurer automatiquement le système à tester sur un environnement physique ou virtuel et par la suite à l’infrastructure as code afin de jouer les TNR sur un environnement éphémère que vous aurez construit puis détruit une fois le résultat des tests obtenus. Vous pouvez enfin intégrer tout cela dans un pipeline de déploiement et commencer à réfléchir sérieusement à une stratégie de livraison continue.
7. Faire évoluer le rôle des testeurs
Le rôle des testeurs évolue au fur et à mesure de la construction de l’automate. Il est intéressant de les considérer comme les premiers utilisateurs, voir comme les product owners de ce nouvel outil. Au tout début, les testeurs passaient beaucoup de temps sur des actions manuelles et répétitives. Petit à petit, leurs activités se sont concentrées sur l’analyse des rapports de test et l’amélioration de l’automate avec comme préoccupation de rendre les TNR de plus en plus facile à réaliser et de produire des rapports de différence toujours plus précis. Le rôle du testeur ne disparaît donc pas avec l’automatisation des TNR; leurs activités peuvent se transformer en quelque chose de plus passionnant s’ils sont complètement embarqués dans l’aventure de l’automatisation.
8. Rester proche de la réalité de production
Il est essentiel d’avoir des données de test représentatives de la production. Ainsi, il vous faut mener régulièrement des campagnes d’analyse des données de production afin de mesurer la pertinence des données de test. Vous découvrez peut être que certaines fonctionnalités ne sont plus utilisées et qu’il est sans doute utile de les enlever de l’application, de même que leurs données de test associées. Le Feature usage tracking est une bonne pratique pour comprendre la manière dont sont utilisées les fonctionnalités en production. Cette pratique peut aider à identifier les scénarios importants pour les ajouter aux données de TNR ou au contraire à enlever ceux qui n’ont plus d’utilité.
Conclusion
L’automatisation des TNR ne se fait pas en un jour mais ce n’est pas quelque chose de compliqué si on se donne comme objectif d’y aller par petit pas et surtout en impliquant les testeurs. La proposition de cet article est de couvrir une grande partie des tests de non-régression en traversant l’application à l’aide de multiple scénarios. Il restera à imaginer des stratégies complémentaires pour tester les autres manières de solliciter l’application, à partir de l’interface utilisateur par exemple.
photo credit: mout1234 Engrenage au Musée des Arts et métiers via photopin (license)
L’automatisation des tests de non-régression (TNR) peut être mise en place assez facilement (avec un peu de développement quand même) à partir de fichiers XML. Dans mon ancienne équipe, les TNR étaient joués à la main, à l’aide d’un comparateur de fichiers XML qui produisait un rapport de différences. Nous avons décidé d’investir dans l’automatisation, ce qui nous a permis d’augmenter le périmètre des TNR et surtout de pouvoir les jouer à volonté. Je partage dans cet article le processus que nous avons mis en place pour vérifier tous les jours plusieurs milliers de calculs.
Votre système n’utilise pas de fichier XML ?
Même si votre système n’utilise pas de fichier XML en entrée et/ou en sortie, il peut être intéressant d’installer des traducteurs XML aux entrées et aux sorties. Cela correspond à donner à votre application la possibilité de lire et produire deux types d’entrée et de sortie. L’un au format habituel et l’autre au format XML.
Dans ce cas, les fichiers XML ne seront utilisés que pour tester la non-régression. Ils ne seront jamais utilisés en production.
Automatiser les tests de non-régression peut se mener en plusieurs étapes, chacune offrant une valeur progressive à votre équipe de testeur. Voici comment peut se décomposer la construction de l’automatisation des TNR:
- Automatiser l’envoie de fichier XML à l’application
- Automatiser la comparaison de fichiers XML
- Organiser les données de test
- Filtrer les données à comparer
- Versionner les données de test
- Améliorer en continue l’automate de test
- Faire évoluer le rôle des testeurs
- Rester proche de la réalité de production
1. Automatiser l’envoie de fichiers XML à l’application
Automatiser l’envoie de plusieurs fichiers XML à l’application offre un premier gain aux testeurs. En effet, ils n’ont plus qu’à solliciter l’application une seule fois pour générer l’ensemble des fichiers XML à comparer.
Il s’agira ici de construire un programme “Injecteur de fichier XML” capable d’envoyer successivement plusieurs fichiers XML d’entrée (correspondant à différents scénarios) à votre application de sorte à ce qu’elle produise des fichiers de résultat correspondant à ces scénarios. La comparaison de fichiers XML résultat avec des fichiers XML de référence reste ici manuelle.
2. Automatiser la comparaison de fichiers XML
L’algorithme de comparaison de fichier XML est assez compliqué. Je recommande l’usage de bibliothèques spécialisées plutôt que d’essayer de développer cet outil soi-même. A l’époque (en 2012), je m’étais tourné vers l’outil de Microsoft Xml Diff and Patch Tool.
L’outil mentionné ci-dessus permet de générer un fichier HTML présentant les différences entre deux fichiers XML. Il précise les différents types de différences comme l’ajout, la suppression, la modification et le déplacement de données XML.
Automatiser la comparaison de fichiers XML revient à être capable non seulement d’injecter des fichiers XML en entrée de l’application mais aussi de récupérer les fichiers XML résultats produit par cette dernière et les comparer à des fichiers XML de référence.
3. Organiser les données de test
L’ensemble des données de test peuvent être stockées dans des dossiers, eux même rangés dans un dossier racine représentant la version de l’application / du système à tester.
Ainsi, en précisant à l’injecteur l’adresse du dossier de test ainsi que celle du dossier où sont produits les fichiers résultats, l’outil est capable d’envoyer successivement les fichiers XML à l’application et comparer les fichiers générés par l’application à des fichiers de référence. Pour identifier facilement les fichiers à comparer, le mieux est de donner un nom similaire aux fichiers d’entrée, de résultat et de référence.
4. Filtrer les données à comparer
Les dates et certaines données varient systématiquement entre deux compagnes de test. Si ces données n’ont pas besoin de faire partie de l’analyse, il est préférable de les enlever des fichiers XML avant le processus de comparaison.
Pour filtrer les fichier XML, il est possible de lister les données à supprimer dans un fichier. Ce dernier sera lu par l’injecteur-comparateur, qui supprimera les attributs et les éléments ciblé par d’expressions xPaths.
Il est possible d’aller plus loin dans la comparaison en proposant un interval de tolérance sur certaines données afin que l’outil ne signale pas d’erreur sur certaines valeurs légèrement différentes.
5. Versionner les données de test
Les données de test doivent être versionnées, au même titre que l’application à tester. Ainsi, comme vous souhaitez tester la non-régression de la version de production (au cas où il y ait une correction de bug à effectuer) et celle de la version en cours de développement, il vous faut maintenir au moins deux jeux de tests de non-régression.
La version en cours de développement permettra de détecter des différences normales par rapport aux résultats des tests de la version précédente. L’équipe de test modifiera les données de test de référence pour la nouvelle version de l’application de sorte à ce que ces différences normales n’existent plus.
6. Améliorer en continue l’automate de test
La construction de l’automate de test (l’injecteur-comparateur) doit se faire de manière incrémentale. Il est possible de démarrer cette initiative en lui consacrant un peu de temps chaque semaine et en visant de petits objectifs qui, mis bout à bout, transformeront complètement la manière de tester la non-régression de l’application. Ainsi, vous pouvez commencer simplement par automatiser l’injection de fichier XML, ce qui apporte déjà de la valeur aux testeurs. Vous pouvez améliorer leur outil de comparaison de fichier XML jusqu’à le rendre capable de comparer un lot de fichiers XML avec des fichiers de référence. Vous pouvez ensuite coupler l’injecteur de fichier XML avec l’outil de comparaison afin de n’avoir qu’à appuyer sur un bouton pour lancer les TNR. Vous pouvez aussi vous intéresser à la manière d’installer et configurer automatiquement le système à tester sur un environnement physique ou virtuel et par la suite à l’infrastructure as code afin de jouer les TNR sur un environnement éphémère que vous aurez construit puis détruit une fois le résultat des tests obtenus. Vous pouvez enfin intégrer tout cela dans un pipeline de déploiement et commencer à réfléchir sérieusement à une stratégie de livraison continue.
7. Faire évoluer le rôle des testeurs
Le rôle des testeurs évolue au fur et à mesure de la construction de l’automate. Il est intéressant de les considérer comme les premiers utilisateurs, voir comme les product owners de ce nouvel outil. Au tout début, les testeurs passaient beaucoup de temps sur des actions manuelles et répétitives. Petit à petit, leurs activités se sont concentrées sur l’analyse des rapports de test et l’amélioration de l’automate avec comme préoccupation de rendre les TNR de plus en plus facile à réaliser et de produire des rapports de différence toujours plus précis. Le rôle du testeur ne disparaît donc pas avec l’automatisation des TNR; leurs activités peuvent se transformer en quelque chose de plus passionnant s’ils sont complètement embarqués dans l’aventure de l’automatisation.
8. Rester proche de la réalité de production
Il est essentiel d’avoir des données de test représentatives de la production. Ainsi, il vous faut mener régulièrement des campagnes d’analyse des données de production afin de mesurer la pertinence des données de test. Vous découvrez peut être que certaines fonctionnalités ne sont plus utilisées et qu’il est sans doute utile de les enlever de l’application, de même que leurs données de test associées. Le Feature usage tracking est une bonne pratique pour comprendre la manière dont sont utilisées les fonctionnalités en production. Cette pratique peut aider à identifier les scénarios importants pour les ajouter aux données de TNR ou au contraire à enlever ceux qui n’ont plus d’utilité.
Conclusion
L’automatisation des TNR ne se fait pas en un jour mais ce n’est pas quelque chose de compliqué si on se donne comme objectif d’y aller par petit pas et surtout en impliquant les testeurs. La proposition de cet article est de couvrir une grande partie des tests de non-régression en traversant l’application à l’aide de multiple scénarios. Il restera à imaginer des stratégies complémentaires pour tester les autres manières de solliciter l’application, à partir de l’interface utilisateur par exemple.
photo credit: mout1234 Engrenage au Musée des Arts et métiers via photopin (license)
L’automatisation des tests de non-régression (TNR) peut être mise en place assez facilement (avec un peu de développement quand même) à partir de fichiers XML. Dans mon ancienne équipe, les TNR étaient joués à la main, à l’aide d’un comparateur de fichiers XML qui produisait un rapport de différences. Nous avons décidé d’investir dans l’automatisation, ce qui nous a permis d’augmenter le périmètre des TNR et surtout de pouvoir les jouer à volonté. Je partage dans cet article le processus que nous avons mis en place pour vérifier tous les jours plusieurs milliers de calculs.
Votre système n’utilise pas de fichier XML ?
Même si votre système n’utilise pas de fichier XML en entrée et/ou en sortie, il peut être intéressant d’installer des traducteurs XML aux entrées et aux sorties. Cela correspond à donner à votre application la possibilité de lire et produire deux types d’entrée et de sortie. L’un au format habituel et l’autre au format XML.
Dans ce cas, les fichiers XML ne seront utilisés que pour tester la non-régression. Ils ne seront jamais utilisés en production.
Automatiser les tests de non-régression peut se mener en plusieurs étapes, chacune offrant une valeur progressive à votre équipe de testeur. Voici comment peut se décomposer la construction de l’automatisation des TNR:
- Automatiser l’envoie de fichier XML à l’application
- Automatiser la comparaison de fichiers XML
- Organiser les données de test
- Filtrer les données à comparer
- Versionner les données de test
- Améliorer en continue l’automate de test
- Faire évoluer le rôle des testeurs
- Rester proche de la réalité de production
1. Automatiser l’envoie de fichiers XML à l’application
Automatiser l’envoie de plusieurs fichiers XML à l’application offre un premier gain aux testeurs. En effet, ils n’ont plus qu’à solliciter l’application une seule fois pour générer l’ensemble des fichiers XML à comparer.
Il s’agira ici de construire un programme “Injecteur de fichier XML” capable d’envoyer successivement plusieurs fichiers XML d’entrée (correspondant à différents scénarios) à votre application de sorte à ce qu’elle produise des fichiers de résultat correspondant à ces scénarios. La comparaison de fichiers XML résultat avec des fichiers XML de référence reste ici manuelle.
2. Automatiser la comparaison de fichiers XML
L’algorithme de comparaison de fichier XML est assez compliqué. Je recommande l’usage de bibliothèques spécialisées plutôt que d’essayer de développer cet outil soi-même. A l’époque (en 2012), je m’étais tourné vers l’outil de Microsoft Xml Diff and Patch Tool.
L’outil mentionné ci-dessus permet de générer un fichier HTML présentant les différences entre deux fichiers XML. Il précise les différents types de différences comme l’ajout, la suppression, la modification et le déplacement de données XML.
Automatiser la comparaison de fichiers XML revient à être capable non seulement d’injecter des fichiers XML en entrée de l’application mais aussi de récupérer les fichiers XML résultats produit par cette dernière et les comparer à des fichiers XML de référence.
3. Organiser les données de test
L’ensemble des données de test peuvent être stockées dans des dossiers, eux même rangés dans un dossier racine représentant la version de l’application / du système à tester.
Ainsi, en précisant à l’injecteur l’adresse du dossier de test ainsi que celle du dossier où sont produits les fichiers résultats, l’outil est capable d’envoyer successivement les fichiers XML à l’application et comparer les fichiers générés par l’application à des fichiers de référence. Pour identifier facilement les fichiers à comparer, le mieux est de donner un nom similaire aux fichiers d’entrée, de résultat et de référence.
4. Filtrer les données à comparer
Les dates et certaines données varient systématiquement entre deux compagnes de test. Si ces données n’ont pas besoin de faire partie de l’analyse, il est préférable de les enlever des fichiers XML avant le processus de comparaison.
Pour filtrer les fichier XML, il est possible de lister les données à supprimer dans un fichier. Ce dernier sera lu par l’injecteur-comparateur, qui supprimera les attributs et les éléments ciblé par d’expressions xPaths.
Il est possible d’aller plus loin dans la comparaison en proposant un interval de tolérance sur certaines données afin que l’outil ne signale pas d’erreur sur certaines valeurs légèrement différentes.
5. Versionner les données de test
Les données de test doivent être versionnées, au même titre que l’application à tester. Ainsi, comme vous souhaitez tester la non-régression de la version de production (au cas où il y ait une correction de bug à effectuer) et celle de la version en cours de développement, il vous faut maintenir au moins deux jeux de tests de non-régression.
La version en cours de développement permettra de détecter des différences normales par rapport aux résultats des tests de la version précédente. L’équipe de test modifiera les données de test de référence pour la nouvelle version de l’application de sorte à ce que ces différences normales n’existent plus.
6. Améliorer en continue l’automate de test
La construction de l’automate de test (l’injecteur-comparateur) doit se faire de manière incrémentale. Il est possible de démarrer cette initiative en lui consacrant un peu de temps chaque semaine et en visant de petits objectifs qui, mis bout à bout, transformeront complètement la manière de tester la non-régression de l’application. Ainsi, vous pouvez commencer simplement par automatiser l’injection de fichier XML, ce qui apporte déjà de la valeur aux testeurs. Vous pouvez améliorer leur outil de comparaison de fichier XML jusqu’à le rendre capable de comparer un lot de fichiers XML avec des fichiers de référence. Vous pouvez ensuite coupler l’injecteur de fichier XML avec l’outil de comparaison afin de n’avoir qu’à appuyer sur un bouton pour lancer les TNR. Vous pouvez aussi vous intéresser à la manière d’installer et configurer automatiquement le système à tester sur un environnement physique ou virtuel et par la suite à l’infrastructure as code afin de jouer les TNR sur un environnement éphémère que vous aurez construit puis détruit une fois le résultat des tests obtenus. Vous pouvez enfin intégrer tout cela dans un pipeline de déploiement et commencer à réfléchir sérieusement à une stratégie de livraison continue.
7. Faire évoluer le rôle des testeurs
Le rôle des testeurs évolue au fur et à mesure de la construction de l’automate. Il est intéressant de les considérer comme les premiers utilisateurs, voir comme les product owners de ce nouvel outil. Au tout début, les testeurs passaient beaucoup de temps sur des actions manuelles et répétitives. Petit à petit, leurs activités se sont concentrées sur l’analyse des rapports de test et l’amélioration de l’automate avec comme préoccupation de rendre les TNR de plus en plus facile à réaliser et de produire des rapports de différence toujours plus précis. Le rôle du testeur ne disparaît donc pas avec l’automatisation des TNR; leurs activités peuvent se transformer en quelque chose de plus passionnant s’ils sont complètement embarqués dans l’aventure de l’automatisation.
8. Rester proche de la réalité de production
Il est essentiel d’avoir des données de test représentatives de la production. Ainsi, il vous faut mener régulièrement des campagnes d’analyse des données de production afin de mesurer la pertinence des données de test. Vous découvrez peut être que certaines fonctionnalités ne sont plus utilisées et qu’il est sans doute utile de les enlever de l’application, de même que leurs données de test associées. Le Feature usage tracking est une bonne pratique pour comprendre la manière dont sont utilisées les fonctionnalités en production. Cette pratique peut aider à identifier les scénarios importants pour les ajouter aux données de TNR ou au contraire à enlever ceux qui n’ont plus d’utilité.
Conclusion
L’automatisation des TNR ne se fait pas en un jour mais ce n’est pas quelque chose de compliqué si on se donne comme objectif d’y aller par petit pas et surtout en impliquant les testeurs. La proposition de cet article est de couvrir une grande partie des tests de non-régression en traversant l’application à l’aide de multiple scénarios. Il restera à imaginer des stratégies complémentaires pour tester les autres manières de solliciter l’application, à partir de l’interface utilisateur par exemple.
photo credit: mout1234 Engrenage au Musée des Arts et métiers via photopin (license)

Bonjour,
Finalement avec quel logiciel faites-vous ça aujourd’hui ? Je cherche un logiciel pour comparer avec tolérances =) Merci